
In the latest Radio-T episode, we mentioned TokuMX - High-Performance MongoDB Distribution. This product sounds interesting — 9x data compression bundled with 20x speed increase and transaction support. At the same time, the transition from mongo to tokumx is quite simple and from an external observer’s point of view — completely transparent. Such magic seemed more than attractive to me and I decided to check how good everything is in practice.
Currently I use several MongoDB systems of different sizes, both in AWS and in private data centers. My usage pattern is mainly oriented toward rare but massive data writes (once a day), somewhat more frequent massive read operations (a set of various analyses), and constant reads to provide data for frontends. I have no particular problems with mongo, except for an approaching (calculated to be in 6 months) disk problem. Data from our system is never deleted and eventually won’t fit on the disks. In AWS, mongo runs on relatively expensive EBS volumes with guaranteed IOPS. I was already planning the conventional solution to the lack of disk space (moving old data to a separate mongo in a cheap configuration), but then TokuMX caught my eye with the promise of 9x compression, which would postpone my problem for the next 4 years. Besides, rollback writes in mongo is only done client-side, and it would be nice to do without this and move it to the server level.
If you’re interested in exactly how TokuMX magic works, welcome to their site. Here I won’t explain what it is and how to configure it, but will share the results of superficial testing. My tests don’t claim scientific accuracy and have the main goal of showing what will happen in my real systems if I switch from mongo to toku.
transparency of transition
Everything’s fine here. In none of my tests covering mongo work (about 200), any problems arose. Everything that worked with mongo works with toku. Integration tests also didn’t reveal any problems, i.e., in my case I can redirect client systems to TokuMX addresses and they’ll continue working without noticing the substitution. I didn’t test the hybrid mode of mongo with toku in one replica set, but I suspect that will work too.
write testing
Tests were conducted on 2 identical virtual machines with 2 processors each, 20GB disk and 1GB RAM. Host computer — MBPR i7, SSD, 16GB RAM. Records (trade candles) for one day were inserted, total 1.4M candles. Average record size 270 bytes. 3 additional indexes (one simple, 2 composite).

As we see, there’s a difference and TokuMX is really faster. Not the promised 20x, of course, but still decent. Although there’s significantly higher CPU load, but this can be expected due to compression.
Data size + indexes in TokuMX also turned out smaller than mongo’s, but only by 1.6 times.
read testing
Reading was tested in a mode close to real usage. All fast queries (by ticker) were performed multiple times for a random selection of 200 tickers, total 10000 queries, result averaged. Interval (by time) queries were performed for 10 random intervals and also multiple times. The same queries in the same order were sent to both mongo and toku. The main goal of this test was to create activity as close to real as possible. Time is given in microseconds.
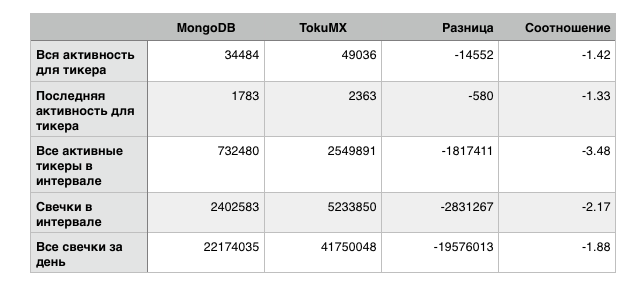
Not believing my eyes, I ran these tests multiple times and similar results (with small fluctuations) repeated consistently. In all my tests, such a difference, where mongo beats tokumx by one and a half to three times, was invariably reproduced.
Deciding that perhaps the issue is that TokuMX needs more CPU, I conducted an unequal battle where a VM with toku with 4 processors competed with mongo on two. The result is somewhat better, but mongo still remains faster even in these unequal conditions (difference on average 1.4 times). The only test in which toku beat mongo (almost 2x) is the last one — all candles for the day.
Thinking about how to test this further, I reduced RAM for both contestants so the dataset wouldn’t fit in memory. Got these results:
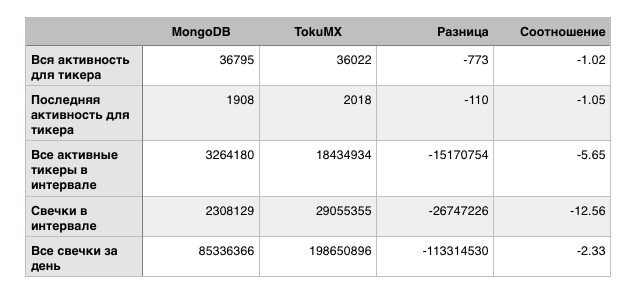
Overall this result looks even worse and the 12x difference doesn’t inspire much optimism. However, the first two tests are noticeably closer to mongo, and in my case the overall result will probably be comparable, since I have many more such “improved” queries than the severely degraded ones.
During testing with small memory amount, I stumbled on a strange peculiarity of toku — if the specified cache size doesn’t fit in available RAM, toku simply truncates the response and of course the client side is very confused by this and starts screaming that data ended earlier than expected.
And one more thing — in all these tests there was mongo “out of the box.” For TokuMX I made concessions in the last test — activated direct IO and set cache size as recommended in their manual.
conclusions
My preliminary conclusion is this: what TokuMX writes about itself, namely “20x faster and 9x more compact out of the box,” in my case isn’t quite true. Practically all read operations were slower (sometimes significantly slower) in TokuMX and the frighteningly silent response truncation also doesn’t cheer me up. For me, transaction support, 1.4x write speedup (no database lock, only document lock), and 1.6x data size gain aren’t worth the significant performance degradation of all read operations.
this note was published by me on habrahabr.ru
This post was translated from the Russian original with AI assistance and reviewed by a human.